@article{xu2025scalable,title={Scalable Chain of Thoughts via Elastic Reasoning},author={Xu, Yuhui and Dong, Hanze and Wang, Lei and Sahoo, Doyen and Li, Junnan and Xiong, Caiming},journal={International Conference on Learning Representation},year={2026}}
Learning to Reason over Continuous Tokens
Yiran Zhao , Yuhui Xu , Doyen Sahoo , and 2 more authors
International Conference on Learning Representation, 2026
@article{zhao2026learning,title={Learning to Reason over Continuous Tokens},author={Zhao, Yiran and Xu, Yuhui and Sahoo, Doyen and Xiong, Caiming and Li, Junnan},journal={International Conference on Learning Representation},year={2026}}
Entropy-Based Block Pruning for Efficient Large Language Models
Liangwei Yang , Yuhui Xu* , Juntao Tan , and 5 more authors
International Conference on Learning Representation, 2026
@article{yang2025entrophy,title={Entropy-Based Block Pruning for Efficient Large Language Models},author={Yang, Liangwei and Xu*, Yuhui and Tan, Juntao and Sahoo, Doyen and Savarese, Silvio and Xiong, Caiming and Wang, Huan and Heinecke, Shelby},journal={International Conference on Learning Representation},year={2026},note={* = corresponding author}}
2025
Lost at the Beginning of Reasoning
Baohao Liao , Xinyi Chen , Sara Rajaee , and 5 more authors
@article{liao2025lost,title={Lost at the Beginning of Reasoning},author={Liao, Baohao and Chen, Xinyi and Rajaee, Sara and Xu, Yuhui and Herold, Christian and Søgaard, Anders and de Rijke, Maarten and Monz, Christof},journal={arXiv preprint arXiv:2506.22058},year={2025}}
Scaling Computer-Use Grounding via User Interface Decomposition and Synthesis
Tianbao Xie , Jiaqi Deng , Xiaochuan Li , and 12 more authors
@article{xie2025scaling,title={Scaling Computer-Use Grounding via User Interface Decomposition and Synthesis},author={Xie, Tianbao and Deng, Jiaqi and Li, Xiaochuan and Yang, Junlin and Wu, Haoyuan and Chen, Jixuan and Hu, Wenjing and Wang, Xinyuan and Xu, Yuhui and Wang, Zekun and Xu, Yiheng and Wang, Junli and Sahoo, Doyen and Yu, Tao and Xiong, Caiming},journal={NeurIPS 2025},year={2025},}
Fractured Chain-of-Thought Reasoning
Baohao Liao* , Hanze Dong* , Yuhui Xu* , and 4 more authors
@article{liao2025fractured,title={Fractured Chain-of-Thought Reasoning},author={Liao*, Baohao and Dong*, Hanze and Xu*, Yuhui and Sahoo, Doyen and Monz, Christof and Li, Junnan and Xiong, Caiming},journal={arXiv preprint arXiv:2505.12992},year={2025},note={* = equal contribution}}
Beyond ’Aha!’: Toward Systematic Meta-Abilities Alignment in Large Reasoning Models
Zhiyuan Hu , Yibo Wang , Hanze Dong , and 5 more authors
@article{hu2025beyond,title={Beyond 'Aha!': Toward Systematic Meta-Abilities Alignment in Large Reasoning Models},author={Hu, Zhiyuan and Wang, Yibo and Dong, Hanze and Xu, Yuhui and Saha, Amrita and Xiong, Caiming and Hooi, Bryan and Li, Junnan},journal={arXiv preprint arXiv:2505.10554},year={2025},}
One QuantLLM for ALL: Fine-tuning Quantized LLMs Once for Efficient Deployments
Ke Yi* , Yuhui Xu* , Heng Chang , and 4 more authors
The 63rd Annual Meeting of the Association for Computational Linguistics (Oral), 2025
@article{yi2024one,title={One QuantLLM for ALL: Fine-tuning Quantized LLMs Once for Efficient Deployments},author={Yi*, Ke and Xu*, Yuhui and Chang, Heng and Tang, Chen and Meng, Yuan and Zhang, Tong and Li, Jia},journal={The 63rd Annual Meeting of the Association for Computational Linguistics (Oral)},year={2025},note={* = equal contribution}}
A Minimalist Approach to LLM Reasoning: from Rejection Sampling to Reinforce
Wei Xiong , Jiarui Yao , Yuhui Xu , and 8 more authors
@article{xiong2025minimalist,title={A Minimalist Approach to LLM Reasoning: from Rejection Sampling to Reinforce},author={Xiong, Wei and Yao, Jiarui and Xu, Yuhui and Pang, Bo and Wang, Lei and Sahoo, Doyen and Li, Junnan and Jiang, Nan and Zhang, Tong and Xiong, Caiming and Dong, Hanze},journal={arXiv preprint arXiv:2504.11343},year={2025}}
Reward Models Identify Consistency, Not Causality
Yuhui Xu , Hanze Dong , Lei Wang , and 2 more authors
@article{xu2025reward,title={Reward Models Identify Consistency, Not Causality},author={Xu, Yuhui and Dong, Hanze and Wang, Lei and Xiong, Caiming and Li, Junnan},journal={arXiv preprint arXiv:2502.14619},year={2025}}
Reward-Guided Speculative Decoding for Efficient LLM Reasoning
Baohao Liao* , Yuhui Xu* , Hanze Dong* , and 5 more authors
International Conference on Machine Learning, 2025
@article{liao2025reward,title={Reward-Guided Speculative Decoding for Efficient LLM Reasoning},author={Liao*, Baohao and Xu*, Yuhui and Dong*, Hanze and Li, Junnan and Monz, Christof and Savarese, Silvio and Sahoo, Doyen and Xiong, Caiming},journal={International Conference on Machine Learning},year={2025},note={* = equal contribution}}
Separated Contrastive Learning for Matching in Cross-domain Recommendation with Curriculum Scheduling
Heng Chang , Liang Gu , Cheng Hu , and 5 more authors
@article{chang2025separated,title={Separated Contrastive Learning for Matching in Cross-domain Recommendation with Curriculum Scheduling},author={Chang, Heng and Gu, Liang and Hu, Cheng and Zhang, Zhinan and Zhu, Hong and Xu, Yuhui and Fang, Yuan and Chen, Zhen},journal={International World Wide Web Conference},year={2025}}
ThinK: Thinner Key Cache by Query-Driven Pruning
Yuhui Xu , Zhanming Jie , Hanze Dong , and 6 more authors
International Conference on Learning Representation (Spotlight), 2025
@article{xu2024think,title={ThinK: Thinner Key Cache by Query-Driven Pruning},author={Xu, Yuhui and Jie, Zhanming and Dong, Hanze and Wang, Lei and Lu, Xudong and Zhou, Aojun and Saha, Amrita and Xiong, Caiming and Sahoo, Doyen},journal={International Conference on Learning Representation (Spotlight)},year={2025},}
2024
GaLore + : Boosting Low-Rank Adaptation for LLMs with Cross-Head Projection
Xutao Liao , Shaohui Li , Yuhui Xu , and 3 more authors
@article{liao2024galore,title={GaLore $+ $: Boosting Low-Rank Adaptation for LLMs with Cross-Head Projection},author={Liao, Xutao and Li, Shaohui and Xu, Yuhui and Li, Zhi and Liu, Yu and He, You},journal={arXiv preprint arXiv:2412.19820},year={2024},}
MathHay: An Automated Benchmark for Long-Context Mathematical Reasoning in LLMs
Lei Wang , Shan Dong , Yuhui Xu , and 6 more authors
@article{wang2024mathhay,title={MathHay: An Automated Benchmark for Long-Context Mathematical Reasoning in LLMs},author={Wang, Lei and Dong, Shan and Xu, Yuhui and Dong, Hanze and Wang, Yalu and Saha, Amrita and Lim, Ee-Peng and Xiong, Caiming and Sahoo, Doyen},journal={arXiv preprint arXiv:2410.04698},year={2024}}
TerDiT: Ternary Diffusion Models with Transformers
Xudong Lu , Aojun Zhou , Ziyi Lin , and 8 more authors
@article{lu2024terdit,title={TerDiT: Ternary Diffusion Models with Transformers},author={Lu, Xudong and Zhou, Aojun and Lin, Ziyi and Liu, Qi and Xu, Yuhui and Zhang, Renrui and Wen, Yafei and Ren, Shuai and Gao, Peng and Yan, Junchi and others},journal={arXiv preprint arXiv:2405.14854},year={2024}}
Not All Experts are Equal: Efficient Expert Pruning and Skipping for Mixture-of-Experts Large Language Models
Xudong Lu , Qi Liu , Yuhui Xu , and 5 more authors
The 62nd Annual Meeting of the Association for Computational Linguistics, 2024
@article{lu2024not,author={Lu, Xudong and Liu, Qi and Xu, Yuhui and Zhou, Aojun and Huang, Siyuan and Zhang, Bo and Yan, Junchi and Li, Hongsheng},title={Not All Experts are Equal: Efficient Expert Pruning and Skipping for Mixture-of-Experts Large Language Models},journal={The 62nd Annual Meeting of the Association for Computational Linguistics},year={2024},}
SPP: Sparsity-Preserved Parameter-Efficient Fine-Tuning for Large Language Models
Xudong Lu* , Aojun Zhou* , Yuhui Xu* , and 3 more authors
International Conference on Machine Learning, 2024
@article{lu2024spp,author={Lu*, Xudong and Zhou*, Aojun and Xu*, Yuhui and Zhang, Renrui and Gao, Peng and Li, Hongsheng},title={SPP: Sparsity-Preserved Parameter-Efficient Fine-Tuning for Large Language Models},journal={International Conference on Machine Learning},year={2024},note={* = equal contribution}}
QA-LoRA: Quantization-aware low-rank adaptation of large language models
Yuhui Xu , Lingxi Xie , Xiaotao Gu , and 6 more authors
International Conference on Learning Representation, 2024
Recently years have witnessed a rapid development of large language models (LLMs). Despite the strong ability in many language-understanding tasks, the heavy computational burden largely restricts the application of LLMs especially when one needs to deploy them onto edge devices. In this paper, we propose a quantization-aware low-rank adaptation (QA-LoRA) algorithm. The motivation lies in the imbalanced degrees of freedom of quantization and adaptation, and the solution is to use group-wise operators which increase the degree of freedom of quantization meanwhile decreasing that of adaptation. QA-LoRA is easily implemented with a few lines of code, and it equips the original LoRA with two-fold abilities: (i) during fine-tuning, the LLM’s weights are quantized (e.g., into INT4) to reduce time and memory usage; (ii) after fine-tuning, the LLM and auxiliary weights are naturally integrated into a quantized model without loss of accuracy. We apply QA-LoRA to the LLaMA and LLaMA2 model families and validate its effectiveness in different fine-tuning datasets and downstream scenarios. The code is made available at https://github.com/yuhuixu1993/qa-lora.
@article{xu2023qa,author={Xu, Yuhui and Xie, Lingxi and Gu, Xiaotao and Chen, Xin and Chang, Heng and Zhang, Hengheng and Chen, Zhensu and Zhang, Xiaopeng and Tian, Qi},title={QA-LoRA: Quantization-aware low-rank adaptation of large language models},journal={International Conference on Learning Representation},year={2024},}
2023
BNET: Batch Normalization With Enhanced Linear Transformation
Yuhui Xu , Lingxi Xie , Cihang Xie , and 6 more authors
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023
Batch normalization (BN) is a fundamental unit in modern deep neural networks. However, BN and its variants focus on normalization statistics but neglect the recovery step that uses linear transformation to improve the capacity of fitting complex data distributions. In this paper, we demonstrate that the recovery step can be improved by aggregating the neighborhood of each neuron rather than just considering a single neuron. Specifically, we propose a simple yet effective method named batch normalization with enhanced linear transformation (BNET) to embed spatial contextual information and improve representation ability. BNET can be easily implemented using the depth-wise convolution and seamlessly transplanted into existing architectures with BN. To our best knowledge, BNET is the first attempt to enhance the recovery step for BN. Furthermore, BN is interpreted as a special case of BNET from both spatial and spectral views. Experimental results demonstrate that BNET achieves consistent performance gains based on various backbones in a wide range of visual tasks. Moreover, BNET can accelerate the convergence of network training and enhance spatial information by assigning important neurons with large weights accordingly.
@article{10012548,author={Xu, Yuhui and Xie, Lingxi and Xie, Cihang and Dai, Wenrui and Mei, Jieru and Qiao, Siyuan and Shen, Wei and Xiong, Hongkai and Yuille, Alan},journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},title={BNET: Batch Normalization With Enhanced Linear Transformation},year={2023},volume={45},number={7},pages={9225-9232},keywords={Task analysis;Convolution;Training;Visualization;Neurons;Kernel;Performance gain;Batch normalization;linear transformation;deep learning},doi={10.1109/TPAMI.2023.3235369}}
2021
Fitting the search space of weight-sharing nas with graph convolutional networks
Xin Chen , Lingxi Xie , Jun Wu , and 3 more authors
@article{chen2021fitting,title={Fitting the search space of weight-sharing nas with graph convolutional networks},author={Chen, Xin and Xie, Lingxi and Wu, Jun and Wei, Longhui and Xu, Yuhui and Tian, Qi},booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},volume={35},number={8},pages={7064--7072},year={2021}}
Partially-Connected Neural Architecture Search for Reduced Computational Redundancy
Yuhui Xu , Lingxi Xie , Wenrui Dai , and 5 more authors
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021
Differentiable architecture search (DARTS) enables effective neural architecture search (NAS) using gradient descent, but suffers from high memory and computational costs. In this paper, we propose a novel approach, namely Partially-Connected DARTS (PC-DARTS), to achieve efficient and stable neural architecture search by reducing the channel and spatial redundancies of the super-network. In the channel level, partial channel connection is presented to randomly sample a small subset of channels for operation selection to accelerate the search process and suppress the over-fitting of the super-network. Side operation is introduced for bypassing (non-sampled) channels to guarantee the performance of searched architectures under extremely low sampling rates. In the spatial level, input features are down-sampled to eliminate spatial redundancy and enhance the efficiency of the mixed computation for operation selection. Furthermore, edge normalization is developed to maintain the consistency of edge selection based on channel sampling with the architectural parameters for edges. Theoretical analysis shows that partial channel connection and parameterized side operation are equivalent to regularizing the super-network on the weights and architectural parameters during bilevel optimization. Experimental results demonstrate that the proposed approach achieves higher search speed and training stability than DARTS. PC-DARTS obtains a top-1 error rate of 2.55 percent on CIFAR-10 with 0.07 GPU-days for architecture search, and a state-of-the-art top-1 error rate of 24.1 percent on ImageNet (under the mobile setting) within 2.8 GPU-days.
@article{9354953,author={Xu, Yuhui and Xie, Lingxi and Dai, Wenrui and Zhang, Xiaopeng and Chen, Xin and Qi, Guo-Jun and Xiong, Hongkai and Tian, Qi},journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},title={Partially-Connected Neural Architecture Search for Reduced Computational Redundancy},year={2021},volume={43},number={9},pages={2953-2970},keywords={Computer architecture;Redundancy;Network architecture;Stability analysis;Microprocessors;Space exploration;Convolution;Neural architecture search;differentiable architecture search;regularization;normalization},doi={10.1109/TPAMI.2021.3059510}}
@article{xu2020latency,title={Latency-aware differentiable neural architecture search},author={Xu, Yuhui and Xie, Lingxi and Zhang, Xiaopeng and Chen, Xin and Shi, Bowen and Tian, Qi and Xiong, Hongkai},journal={arXiv preprint arXiv:2001.06392},year={2020}}
Trp: Trained rank pruning for efficient deep neural networks
Yuhui Xu , Yuxi Li , Shuai Zhang , and 6 more authors
International Joint Conference on Artificial Intelligence, 2020
@article{xu2020trp,title={Trp: Trained rank pruning for efficient deep neural networks},author={Xu, Yuhui and Li, Yuxi and Zhang, Shuai and Wen, Wei and Wang, Botao and Qi, Yingyong and Chen, Yiran and Lin, Weiyao and Xiong, Hongkai},journal={International Joint Conference on Artificial Intelligence},year={2020}}
PC-DARTS: Partial Channel Connections for Memory-Efficient Architecture Search
Yuhui Xu , Lingxi Xie , Xiaopeng Zhang , and 4 more authors
International Conference on Learning Representation (Spotlight), 2020
Differentiable architecture search (DARTS) provided a fast solution in finding effective network architectures, but suffered from large memory and computing overheads in jointly training a super-network and searching for an optimal architecture. In this paper, we present a novel approach, namely, Partially-Connected DARTS, by sampling a small part of super-network to reduce the redundancy in exploring the network space, thereby performing a more efficient search without comprising the performance. In particular, we perform operation search in a subset of channels while bypassing the held out part in a shortcut. This strategy may suffer from an undesired inconsistency on selecting the edges of super-net caused by sampling different channels. We alleviate it using edge normalization, which adds a new set of edge-level parameters to reduce uncertainty in search. Thanks to the reduced memory cost, PC-DARTS can be trained with a larger batch size and, consequently, enjoys both faster speed and higher training stability. Experimental results demonstrate the effectiveness of the proposed method. Specifically, we achieve an error rate of 2.57% on CIFAR10 with merely 0.1 GPU-days for architecture search, and a state-of-the-art top-1 error rate of 24.2% on ImageNe (under the mobile setting) using 3.8 GPU-days for search. Our code has been made available at https://github.com/yuhuixu1993/PC-DARTS
@article{xu2019pc,author={Xu, Yuhui and Xie, Lingxi and Zhang, Xiaopeng and Chen, Xin and Qi, Guo-Jun and Tian, Qi and Xiong, Hongkai},title={PC-DARTS: Partial Channel Connections for Memory-Efficient Architecture Search},journal={International Conference on Learning Representation (Spotlight)},year={2020},}
Iterative Deep Neural Network Quantization With Lipschitz Constraint
Yuhui Xu , Wenrui Dai , Yingyong Qi , and 2 more authors
Network quantization offers an effective solution to deep neural network compression for practical usage. Existing network quantization methods cannot theoretically guarantee the convergence. This paper proposes a novel iterative framework for network quantization with arbitrary bit-widths. We present two Lipschitz constraint based quantization strategies, namely width-level network quantization (WLQ) and multi-level network quantization (MLQ), for high-bit and extremely low-bit (ternary) quantization, respectively. In WLQ, Lipschitz based partition is developed to divide parameters in each layer into two groups: one for quantization and the other for re-training to eliminate the quantization loss. WLQ is further extended to MLQ by introducing layer partition to suppress the quantization loss for extremely low bit-widths. The Lipschitz based partition is proven to guarantee the convergence of the quantized networks. Moreover, the proposed framework is complementary to network compression methods such as activation quantization, pruning and efficient network architectures. The proposed framework is evaluated over extensive state-of-the-art deep neural networks, i.e., AlexNet, VGG-16, GoogleNet and ResNet18. Experimental results show that the proposed framework improves the performance of tasks like classification, object detection and semantic segmentation.
@article{8884243,author={Xu, Yuhui and Dai, Wenrui and Qi, Yingyong and Zou, Junni and Xiong, Hongkai},title={Iterative Deep Neural Network Quantization With Lipschitz Constraint},journal={IEEE Transactions on Multimedia},volume={22},year={2020},number={7},pages={2079-9292},doi={10.3390/electronics10161912}}
2019
DNQ: Dynamic network quantization
Yuhui Xu , Shuai Zhang , Yingyong Qi , and 3 more authors
@article{xu2018dnq,title={DNQ: Dynamic network quantization},author={Xu, Yuhui and Zhang, Shuai and Qi, Yingyong and Guo, Jiaxian and Lin, Weiyao and Xiong, Hongkai},journal={IEEE DCC},year={2019}}
2018
Deep neural network compression with single and multiple level quantization
Yuhui Xu , Yongzhuang Wang , Aojun Zhou , and 2 more authors
In Proceedings of the AAAI conference on artificial intelligence , 2018
@inproceedings{xu2018deep,title={Deep neural network compression with single and multiple level quantization},author={Xu, Yuhui and Wang, Yongzhuang and Zhou, Aojun and Lin, Weiyao and Xiong, Hongkai},booktitle={Proceedings of the AAAI conference on artificial intelligence},volume={32},number={1},year={2018},}


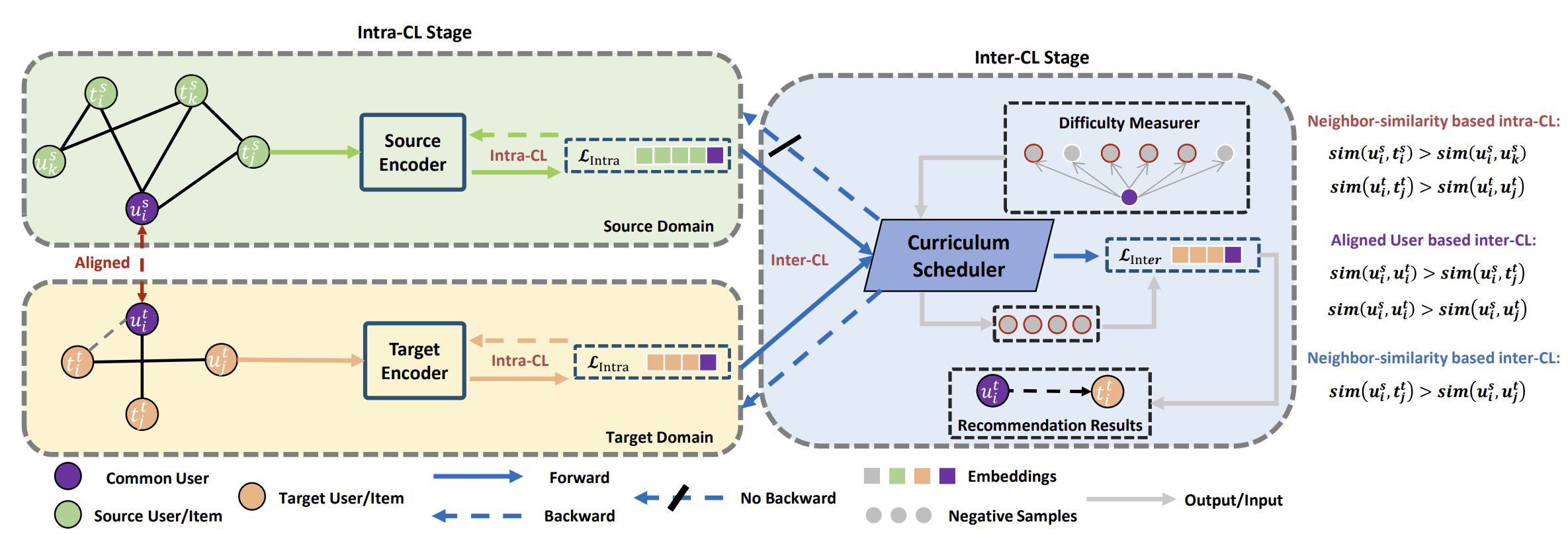 Separated Contrastive Learning for Matching in Cross-domain Recommendation with Curriculum SchedulingInternational World Wide Web Conference, 2025
Separated Contrastive Learning for Matching in Cross-domain Recommendation with Curriculum SchedulingInternational World Wide Web Conference, 2025






















